
Four bibliographic data science challenges and suggestions for solving them
Towards cooperation between researchers and libraries
This post is the extended version of a five minute presentation held in the panel How to provide and use bibliographical data for research—the example of the VD17 at DARIAH Annual Event 2025 (Göttingen, 2025 June 18.) It discusses some of the technical challenges to using library catalogues as data sources for the kind of research we are also doing.
Library catalogues hold the information necessary for answering such questions as what percentage of all American publications are translations from other languages, or who were the people who translated fictional works published in France between 1970-1979, or what were the most important source languages of translations into English, or what percentage of books in a given year were published by a specific publisher, for example. Getting this information from a library catalog is a complex task—this post is an overview of how it can be done. I would like to thank to János Káldos for thinking together on this concept.
How to extract information from library catalogue records?
Let's suppose that we are Digital Humanities researchers, who would like to use information stored in a library catalogue as a data source for cultural history, and have access to the records in a library catalogue. Such access is not as straightforward as you might think, and it comes with several legal and technical challenges, but this time we put these aside, and suppose that we have some files in a file system directory that we can at least read. Catalogues in Europe are mostly (but by no means exclusively) in one of three popular bibliographic metadata schemas: MARC21, PICA and UNIMARC. Each schema can be serialized into different file formats. For MARC21 and UNIMARC there is a standardized binary ISO format (ISO 2709), an XML based format (MARCXML), and a number of plain text formats, e.g. Alephseq, MARC Line, MARCMaker, and even JSON versions. There are also line separated binary, XML or JSON versions, where each line contains a single record. For PICA there is also an XML version, and it also has plain text based versions, such as PICA plain, and PICA normalized. Johan Rolschewski created a nice introductory website Processing MARC 21 where you can find additional information about these formats.
For processing bibliographic records we do not have an abundance of tools. The first factor of choosing a tool probably is your preference of programming language. There are tools for Java, Python, PHP, Go, even JavaScript. But most of these tools are not comprehensive, they do not cover all serialization formats. If the tool of your choice does not fit the file format, you can try conversion tools, such as yaz-marcdump, or Catmandu (however none of these supports all serialization formats). You can find tools on Github by tags, such as #marc, #marc21, #marc-records, #pica, #unimarc, #code4lib—but be aware that some of these tags have multiple meanings, and they might refer to tools beyond the bibliographic universe (there are repositories belonging to a Manga character whose name is also transliterated as Pica).
How to understand bibliographic records?
Once you are able to read the records, you will find that (unlike most of XML or JSON records) the names of data elements are encoded with alphanumeric identifiers rather than in natural language. Here is a MARC21 record from the Polish Literary Bibliography in one of the serialization formats mentioned:
=LDR 00672nab-a22001814u-4500
=001 pl000389252
=005 20090902
=008 090902s1996----pl\\\\\\\\\\\\\\\\\\pol\\
=040 \\$aIBL$bpol
=245 10$aMrożek wraca? /$c[no author]
=380 \\$iMajor genre$aSecondary literature$leng
=520 2\$anota o planowanym powrocie do Polski
=600 14$aMrożek, Sławomir$d(1930-2013)$1http://viaf.org/viaf/71395393
=650 04$aHasła osobowe (literatura polska)
=650 \7$aPolish literature$2ELB-n
=655 \4$aArtykuł
=773 0\$tGazeta Wyborcza$x0860-908X$gR. 1996, nr 90, s. 1$91996$sGazeta Wyborcza
=995 \\$aPolska Bibliografia Literacka$bPBL 1989-2003: książki i czasopismaAs you can see, not only the data elements' names are encoded (e.g. instead of title, it uses 245$a), but some of the content as well (the language of cataloging is ‘pol’ for Polish in 040$b, the ‘n’ in the 6th character of the first line means that the record’s status is ‘new’).
Even when the content itself seemingly is not encoded, behind the scenes there are many content related transcription and transliteration rules and conventions. The most important ones are (the older) AACR2 in the Anglo-Saxon world, ISBD elsewhere, and recently RDA. These standards rely on typographical conventions and graphical symbols (such as comma, dot, colon, slash, parentheses, exclamation mark) as content delimiters or qualifiers to separate semantic elements within the same bibliographic data element, or to add some semantic layer. For example, if the publication year is in square brackets, it means that it was not mentioned in the primary sources of the book description (it does not appear on the title page, for example), and the cataloguer has found it somewhere else. AACR2 and ISBD are freely available as PDF documents, but RDA is published behind a paywall, it is not accessible for researchers (unless you conduct research within a member library).
With Jakob Voß and Haris Gegić we have created machine readable versions of the following bibliographic standards: PICA (for PICA3 and and PICA+ dialects), MARC21 bibliographic and UNIMARC in JSON. We also created a JSON schema called Avram Schema (after Henriette Avram, the inventor of MARC, an engineer at the Library of Congress), that provides a property set to create representations of the rules of these standards. These schema files can easily be paired with the raw structure of the bibliographical records, thus we can inject a ‘semantic layer’ into the record that could be used in parsing, analysis, search, and quality assessment—for example to make it easily decidable if a given data element is part of the standard or not, or whether a given subfield is repeatable. The schemas contain a list of encoded values, so we can resolve such codes into English phrases.
We also try to convince libraries to publish the documentation of their locally defined data elements, and about a dozen such extensions are also available as Avram compatible metadata schema representations. Parallel with us, others, such as Tim Thompson (Yale) and Ed Summers (Stanford) also created similar JSON representations. Avram does not yet contain all properties of the standards: for instance, we can not yet encode the cataloging examples or longer descriptions of the subfields found in the the original metadata documentation—there is room to improve both Avram and the specific JSON files we have created. Another thing we still lack are JSON representations of the content standards AACR2, ISBD and RDA. As a community we should create them in order to improve the understandability of the bibliographic records.
Granularity and normalization
The next issue a researcher has to face is that some information is available only in descriptive data elements, and the entities mentioned there (persons, roles, place names, dates—the who, where, when and what part) are not available as contextual information i.e. as normalized values registered in authority entries. Let's see the following phrase from the subfield 245$c of a record found in BOSLIT, the Bibliography of Scottish Literature in Translation:
John McGrath - [herausgegeben von Günther Klotz - aus dem Englischen übersetzt von Ingeborg Gronke und Eva Walch]
What we see here is a sentence-like structure that was created following general and local cataloguing rules. The granularity of this information might be different than what a researcher expects: in this case, individual names listed with the type of contribution in distinct fields and subfields is necessary for the analysis of the agency involved, whereas texts like this are of course useful in a nicely formatted bibliography. If we want to respond to a research question such as who are the German translators of English drama, we should be able to list individual persons, but it can not be done directly from the sentence. We should extract four persons with their corresponding roles, and then we can find some identifiers of them. The end result would be something like:
author: John McGrath (https://isni.org/isni/0000000114479436)
editor: Günther Klotz (https://d-nb.info/gnd/132185962)
translator: Ingeborg Gronke
translator: Eva Walch (https://viaf.org/viaf/165673546/)
For the editor and the translator the roles come from explicit textual information (‘herausgegeben von’ i.e. edited by and ‘übersetzt von’ i.e. translated by). Since the author is not denoted explicitly, we infer this information from its position as the first name in the list.
The information extraction (John McGrath is the author), normalization (e.g. transform a "McGrath, John" form to the corresponding standardised name form) and entity linking (providing an dereferenceable identifier to a vocabulary of authority names, e.g. VIAF, ISNI, or Wikidata) are not trivial processes. Fortunately there are some repositories that contain software code written for this purpose, so we are in a rather good position in extracting and normalizing dates, or page numbers. Place name extraction is a more difficult process (because of historical and declined forms, orthographical and language variants), and processing complex sentences such as the above example is even more challenging. It also doesn’t make life easy that these software codes are parts of larger packages created for supporting a particular research, and not for reusing in other projects, which means they are sometimes interconnected with other functionalities irrelevant to our purpose.
As a community, we should however map these functionalities, and also provide guidance to developers what is possible with which tools. We could also coordinate some further development activities for extraction, normalization and linking for data elements not covered thus far.
Data roundtrip
Provided that we have solved these challenges and we have perfect data, we are ready to run data analyses to test our domain specific hypotheses (e.g. is it true that a greater proportion of printed books were in vernaculars in the 17th century than in the 16th? or is it true that during the Cold War the Soviet Union had less impact on the publication sector than in the political sector in the Central East European countries?). But what if somebody else would like to test her own hypotheses on the same catalogue? Should she run the same—quite long—preprocessing workflow starting from scratch? Wouldn't it be better if we could somehow set up another workflow in the reverse direction, and give back the ‘improved’ or ‘enhanced’ data to the library?
I envisage a workflow among three players: 1) cultural heritage organizations (libraries), 2) researchers, 3) research community.
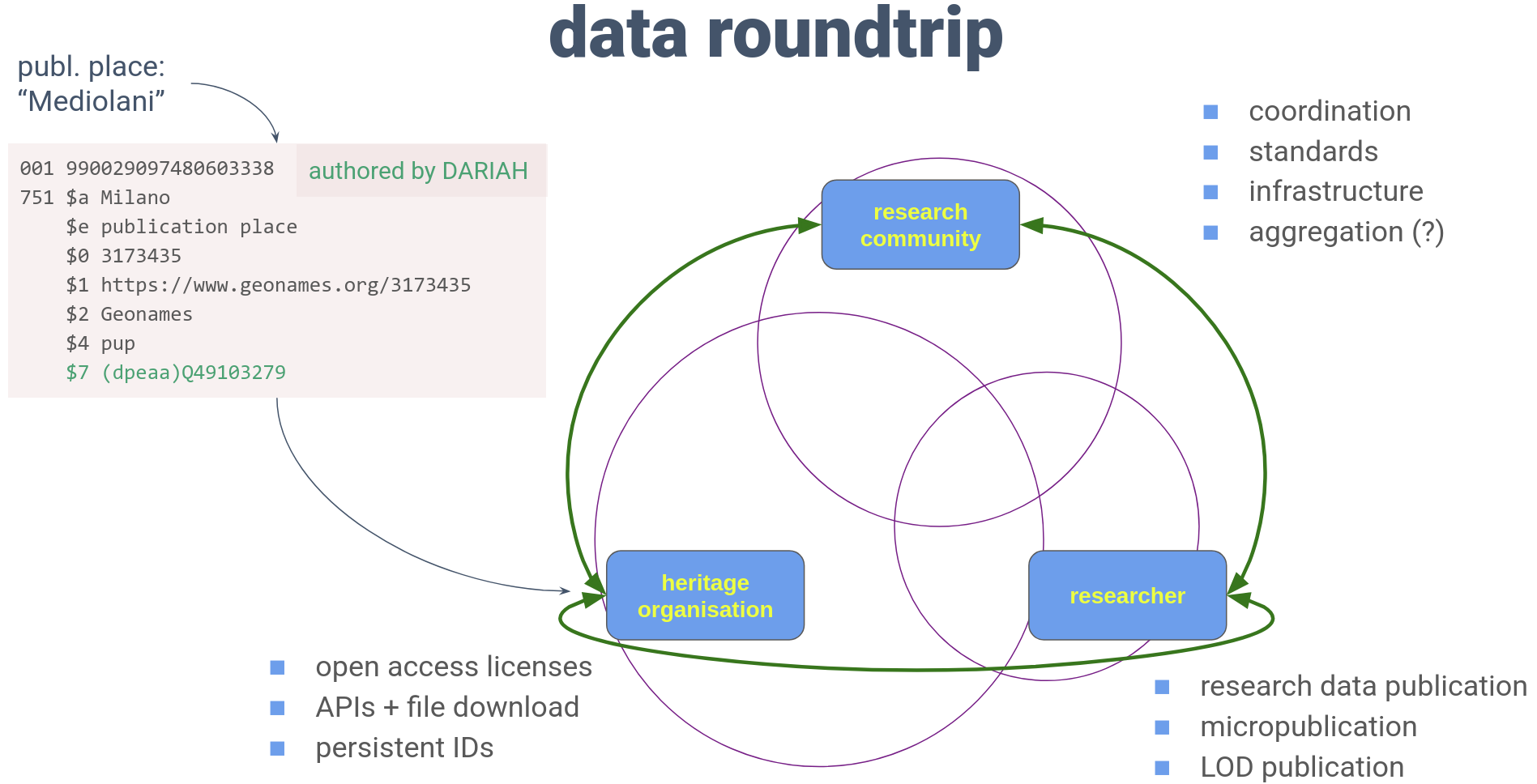
Let’s suppose we have a record with ‘Mediolani’ as the publication place. It means ‘In Milan’ in Latin. So its normalized form in ‘Milan’, its identifier is: https://www.geonames.org/3173435. What steps can we do in order that the next researcher will be able to access this information in the catalogue record? Right now there is no clearly defined procedure to give it back to the library. One possible suggestion would be nanopublication. This concept comes from biology and it means that the researcher publishes small, atomic, but meaningful, reusable data units. In our case the nanopublication would contain the identifier of the record, and a formalized statement, expressing that the publication place is Milan. But here comes the next problem: the cataloguing activity requires special training and knowledge. The library takes responsibility for the catalogue. If they take the data from a researcher, they should be able to clearly separate the part of the catalogue record that was produced by them from the user (i.e. researcher) generated content. There are two approaches to making this distinction. 1) In the Europeana Data Model there is User Generated Content (edm:ugc) data element for this separation, where Europeana could collect all annotations coming from users. 2) In recent years MARC21 introduced a generic subfield for recording provenance information that is available in many fields. Using this subfield, we can format our nanopublication as
001 990029097480603338
751 $a Milano
$e publication place
$0 3173435
$1 https://www.geonames.org/3173435
$2 Geonames
$4 pup
$7 (dpeaa)Q49103279001 is the record identifier, 751 is for recording authorised geographic names, $a denotes the geographic name itself, $e and $4 denote its role in the record (here: place of publication), $2 denotes the vocabulary, $0 is the identifier, $1 is a URL, and finally $7 contains the data provenance, where "dpeaa" means that we name the author of the entry, and that name is ‘Q49103279’, the Wikidata identifier of DARIAH (after all, this presentation was held in a DARIAH conference). So this statement could be expressed in human words as “according to DARIAH, the publication place of the record is Milan.” Parallel with this MARC21 based approach there might be other approaches, e.g. based on Linked Open Data technology.
But in order to make this concept work the parties would need to do some homework.
The heritage organizations should assign clear license statements to their data. They should also provide data accessing methods (APIs and file download options). The records should have a persistent and resolvable identifier. And—as this is a wish list—versioning of both the metadata standards and the records would be a valuable component of a library catalogue (MARC21 standard has updates twice a year including additions and removals, but no field in the bibliographic record to tell us which version it was intended to fit). A big question is how the metadata records could be updated with retrieved information in the current existing library management systems.
The research community should have a coordination role on creating content standards and communication mechanisms for the nanopublications that are both acceptable and viable for both the researchers as data producers, and libraries as data consumers. It might have a role in setting up supporting infrastructure, and maybe as an aggregator of the data.
Finally the researchers most importantly should share their data. They should also participate in the standardization process, and follow the guidelines created by the research community.
If we could create a framework for this workflow, it could be useful for both parties with only a minimal overhead (once the infrastructure components are ready on all sides). Such a workflow requires intensive communication and agreement between the three players involving the metadata standardization committees, large, innovative libraries, the bibliodata related working groups of digital humanities and library organizations, and bibliodata researchers.
Let’s start a conversation about the next steps!
Appendix A
Some papers discussing data problems of MARC21:
Roy Tennant. (2002.) “MARC must die.” Library Journal 41, 4 (2002), 185–
194. http://lj.libraryjournal.com/2002/10/ljarchives/marc-must-die/
Jason Thomale. (2010.) “Interpreting MARC: Where’s the Bibliographic Data?”
Code4Lib Journal, Issue 11, 2010-09-21. https://journal.code4lib.org/articles/3832
Karen Coyle. (2011.) “MARC21 as Data: A Start.” Code4Lib Journal, Issue 14, 2011-07-25. https://journal.code4lib.org/articles/5468
Shieh, Jackie and Reese, Terry. (2016). “The Importance of Identifiers in the New Web Environment and Using the Uniform Resource Identifier (URI) in Subfield Zero ($0): A Small Step That Is Actually a Big Step.” Journal of Library Metadata, (3-4), 208-226. 10.1080/19386389.2015.1099981
Appendix B
Some bibliographic data science papers:
Andrew Prescott. (2013). “Bibliographic Records as Humanities Big Data.” In 2013 IEEE International Conference on Big Data, 55–58, 2013. 10.1109/BigData.2013.6691670
Michael F. Suarez. (2009). “Towards a bibliometric analysis of the surviving record, 1701–1800.” in The Cambridge History of the Book in Britain, Volume 5: 1695–1830, Cambridge University Press, 2009. pp. 37-65. 10.1017/CHOL9780521810173.003
Sandra Tuppen, Stephen Rose, and Loukia Drosopoulou (2016). “Library Catalogue Records as a Research Resource: Introducing ‘A Big Data History of Music.’” Fontes Artis Musicae 63, no. 2:67–88. 10.1353/fam.2016.0011
Tolonen, M., Mäkelä, E., Marjanen, J., Kanner, A., Lahti, L., Ginter, F., Salmi, H., Vesanto, A., Nivala, A., Rantala, H., & Sippola, R. (2018). “Metadata analysis and text reuse detection: Reassessing public discourse in Finland through newspapers and journals 1771–1917.” Paper presented at digital humanities in the Nordic countries DHN2018, Helsinki, Finland. researchportal.helsinki.fi
Lahti, L., Marjanen, J., Roivainen, H., & Tolonen, M. (2019). “Bibliographic data science and the history of the book (c. 1500–1800).” Cataloging & Classification Quarterly, 57(1), 5–23. 10.1080/01639374.2018.1543747
Marjanen, J., Kurunmäki, J. A., Pivovarova, L., & Zosa, E. (2020). “The expansion of isms, 1820–1917: Data-driven analysis of political language in digitized newspaper collections.” Journal of Data Mining and Digital Humanities, HistoInformatics, 1–28. https://jdmdh.episciences.org/6728
Mikko Tolonen, Mark J. Hill, Ali Ijaz, Ville Vaara, Leo Lahti. (2021). “Examining the Early Modern Canon : The English Short Title Catalogue and Large-Scale Patterns of Cultural Production.” In Ileana Baird (eds.) Data Visualization in Enlightenment Literature and Culture. Cham : Palgrave Macmillan, 2021. pp. 63-119 10.1007/978-3-030-54913-8_3
Simon Burrows. (2021). “In Search of Enlightenment: From Mapping Books to Cultural History.” In: Ileana Baird (eds) Data Visualization in Enlightenment Literature and Culture. Palgrave Macmillan, Cham. 10.1007/978-3-030-54913-8_2